
I am Gaël (pron. [gah-el]), senior machine learning research scientist at LawZero, a nonprofit organization created by Yoshua Bengio. I work on building the ScientistAI, a safe-by-design AI system that can reason and discover new scientific knowledge about the world.
I focus on making safe, reliable and robust AI based on factuality and causality, with a particular interest in large reasoning models (LLMs/LRMs).
I showcased my work at top AI conferences and received the University of Auckland Best Student Published Paper in Computer Science award in 2023.
As part of my work, I conducted the first evaluation of large language models (LLMs) on abstract reasoning, highlighting their brittleness and limitations.
I developed ICLM, a novel modular language model architecture based on causal principles for out-of-distribution reasoning, and showed that causal models
can improve the learning of interpretable, robust and domain-invariant mechanisms. My latest work, the Causal Cartographer is the first end-to-end framework for causal extraction and inference with LLM agents, enabling them to reason more reliably and efficiently in counterfactual environments (decreasing inference cost by up to 70%).
Latest Research
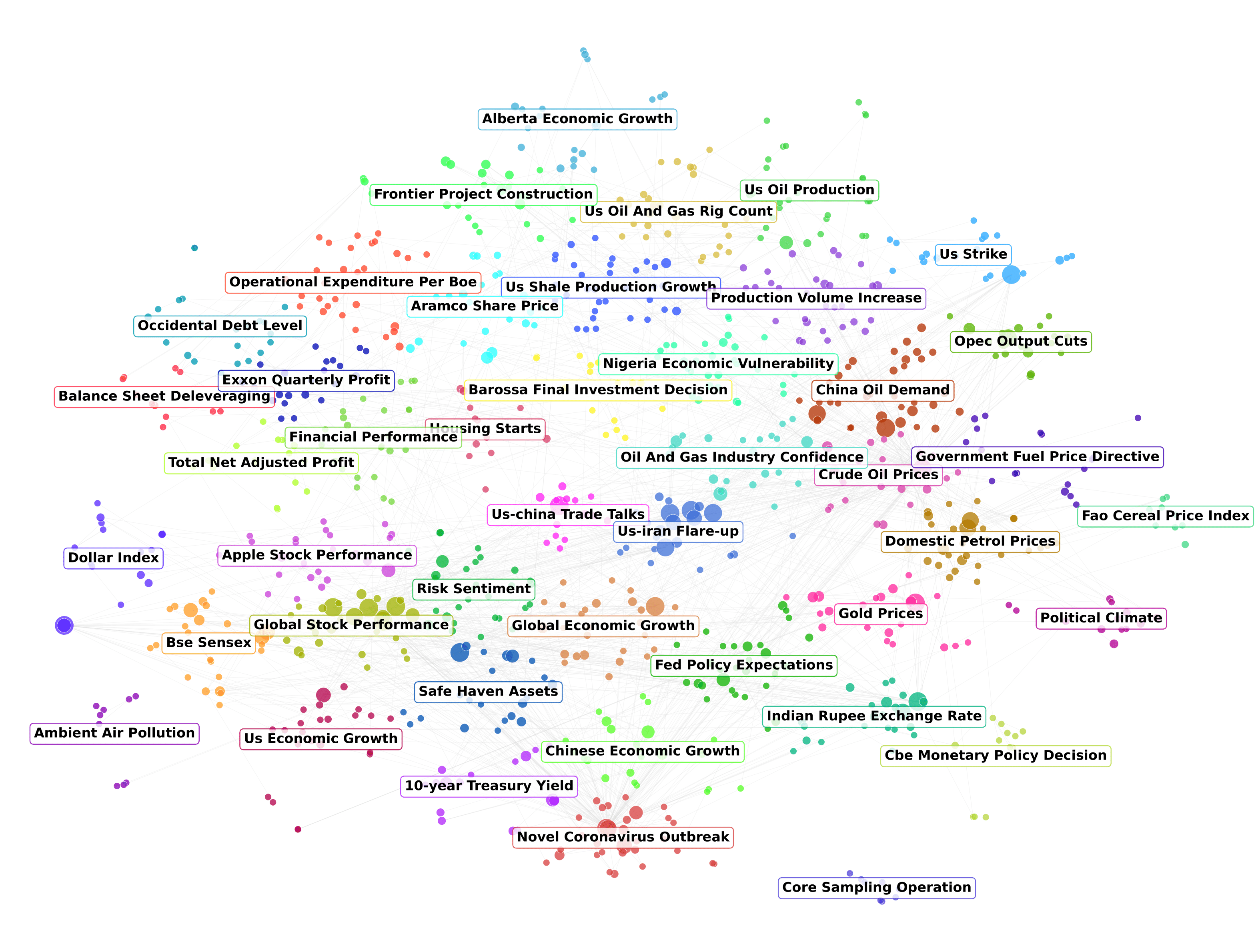
Causal Cartographer: From Mapping to Reasoning Over Counterfactual Worlds
We introduce a retrieval-augmented system for causal extraction and representating causal knowledge, and a methodology for provably estimating real-world counterfactuals. We show that causal-guided step-by-step LRMs can achieve competitive performance while greatly reducing LLMs' context and output length, decreasing inference cost up to 70%.
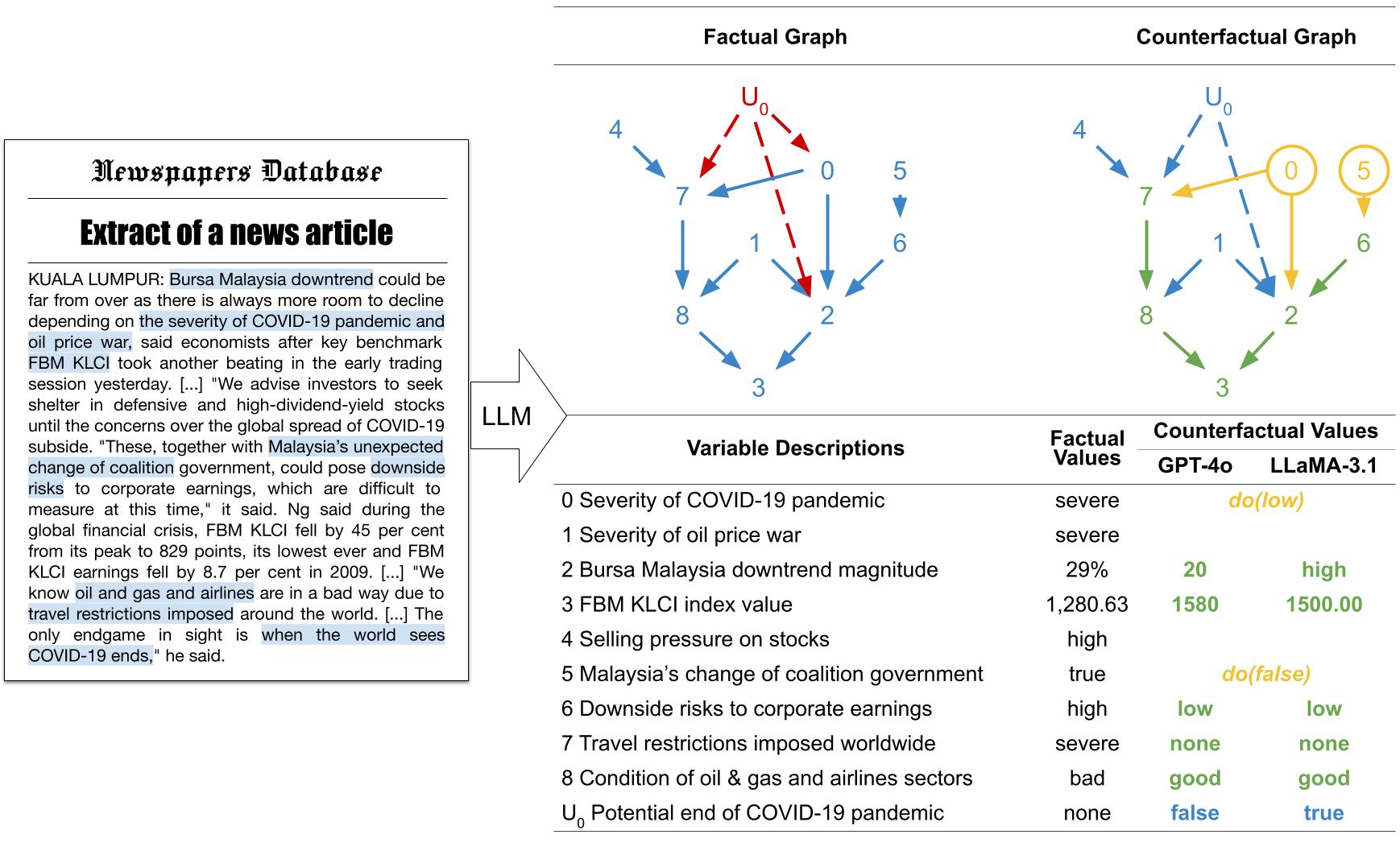
Counterfactual Causal Inference in Natural Language
We build the first causal extraction and counterfactual causal inference system for natural language, and propose a new direction for model oversight and strategic foresight.
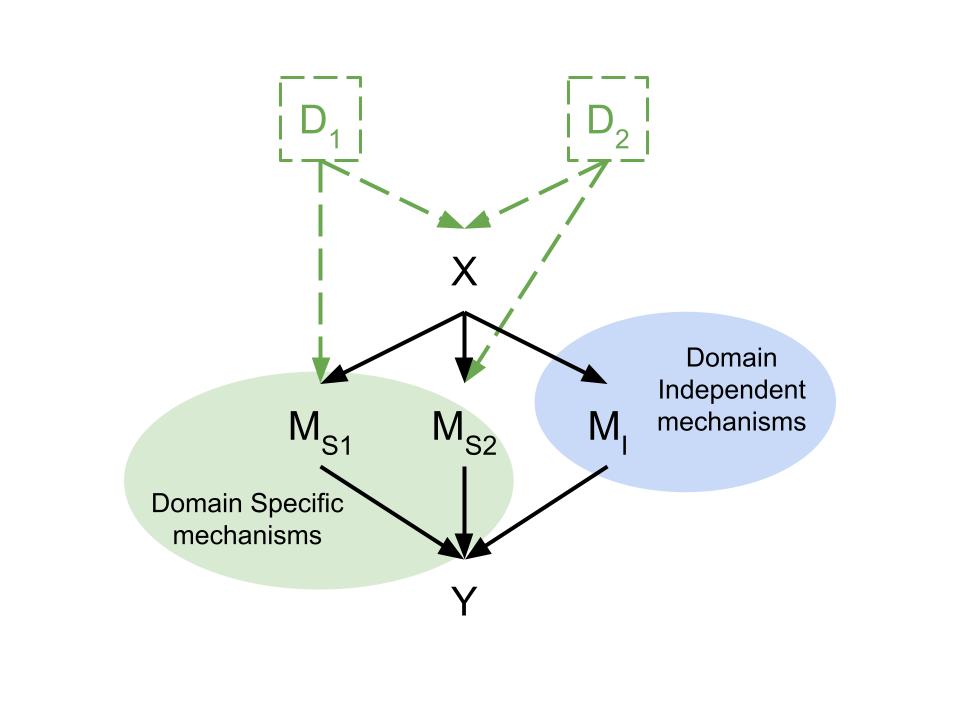
Independent Causal Language Models
We develop a novel modular language model architecture sparating inference into independant causal modules, and show that it can be used to improve abstract reasoning performance and robustness for out-of-distribution settings.

Behaviour Modelling of Social Agents
We model the behaviour of interacting social agents (e.g. meerkats) using a combination of causal inference and graph neural networks, and demonstrate increased efficiency and interpretability compared to existing architectures.

Large Language Models Are Not Strong Abstract Reasoners
We evaluate the performance of large language models on abstract reasoning tasks and show that they fail to adapt to unseen reasoning chains, highlighting a lack of generalization and robustness.
